Exploring Claude 3 feels like stepping into a new era of intelligent AI assistants. Anthropic designed Claude 3 to be more intuitive and practical for a range of complex tasks. Testers highlight its careful reasoning and improved security. Early tests show faster coding performance, while independent studies highlight improved safety. Professionals also confirm better handling of complex instructions.
The model supports project planning, document rewriting, and text summarization. For businesses and creators, reviews of Anthropic Claude 3 offer valuable insights. Professionals report that it handles complex instructions with clear, step-by-step responses and maintains context longer in conversations, streamlining research and drafting tasks across industries.
The model manages longer conversations without losing focus and better understands user intent. When necessary, it refers back to earlier points and reads the context. The model provides step-by-step plans and answers questions. To lessen detrimental outputs, Anthropic concentrated on safety training and scalable supervision. Adopters report fewer strange hallucinations and more fluid role-playing and creative writing.
With the help of fine-tuning tools and APIs, organizations can modify Claude 3 to fit particular workflows. Performance improvements are evident in tasks involving document analysis, summarization, and code assistance. Independent tests and reviews frequently highlight Claude 3’s performance and safety. To free up human personnel for higher-level decisions while maintaining consistency in the quality and tone of all communications, enterprise teams utilize the model to automate reporting, draft customer messages, and triage complex emails.
Benchmark results show Claude 3 excels in reasoning tasks, often matching or surpassing leading models. It performs exceptionally well in coding challenges and debugging exercises. Lower latency makes web apps and professional tools feel more responsive. Real-world use cases include summarizing reports and extracting insights from large documents.
Organizations use A/B testing to measure outcomes and business impact. Human reviewers identify edge cases and refine prompts for greater reliability. Thorough evaluations help teams choose high-value tasks for safe automation. While governance teams oversee logging and reviews, users report faster decision-making and reduced repetitive work when integrating the model into workflows.
Claude 3 training and deployment placed a high priority on safety and alignment—anthropic shaped model responses based on input from human reviewers and red teams. Guardrails maintain factual and helpful responses while limiting harmful suggestions. Safe alternatives and clarifying questions are triggered by prompts that request dangerous or unlawful actions. Refusal accuracy on risky requests was increased through fine-tuning using human critique and reinforcement.
Organizations can examine the model’s reasoning for decisions or recommendations using transparency tools. Through feedback channels, professionals can identify problematic outputs and contribute to the improvement of upcoming updates. For applications in delicate fields like healthcare, careful tuning strikes a balance between creativity and prudence. Regular audits guarantee that the model complies with changing safety standards across jurisdictions and legal teams, and governance policies combine automated checks with human review to identify infrequent failures.

To link Claude 3 to applications and backends, developers receive SDKs and APIs. Integration for routine tasks is sped up by clear documentation and example prompts. At the application layer, businesses can apply safety filters and adjust prompts. When necessary, enterprises can add features like file handling and web browsing thanks to plugin ecosystems. Support libraries make rate control and authentication easier for production use.
To monitor model usage and output quality over time, teams create monitoring dashboards. Repetitive prompt engineering work is decreased, and a consistent tone is maintained with the use of shared prompt libraries. Anthropic publishes best practices to direct integrations and promote conscientious deployments. Partner programs facilitate quicker adoption and easier handoffs between ML engineers and product teams globally by assisting small vendors in integrating the model into specialized tools and offering training materials for enterprise personnel.
Claude 3 is used in a variety of fields, including software, marketing, and education. Lesson plans and reading summaries that align with classroom objectives are available to teachers. Before launch, marketers test campaign drafts and refine messaging. Business units draft onboarding flows and user manuals using the model. Summarization tools help legal teams examine contracts more quickly while maintaining human oversight.
Customer service teams use Claude 3 to prioritize tickets for agents and offer suggestions for responses. Before being used in clinical settings, medical researchers rely on meticulous summarization and expert review. Clear human oversight, domain expertise, and governance are necessary for adoption. Early adopters highlight that human experts must always verify outputs for accuracy and compliance before final publication or decision-making, but they also report time savings and increased consistency.
Future updates will strengthen professional tools and improve model robustness. Anthropic will probably increase integrations with partner platforms and improve safety efforts. There are still unanswered concerns regarding cost, governance, and regional variations in regulations. Small team priorities and feature roadmaps will be influenced by community input. Scholars will investigate model boundaries and disseminate results that promote safer usage.
Companies will balance automation with the need for human supervision in sensitive workflows. Regulators may establish new guidelines for reporting, testing, and disclosures on AI deployments. Claude 3 will be most useful to users who understand prompt design and validation practices. Adoption will increase in areas with a definite return on investment and where departments make investments in staff training, monitoring, and timely libraries to collaborate with AI assistants for better results now.
Claude 3 marks a major step toward safer, more efficient large language models. This review helps organizations determine if it suits their needs. Fair evaluations emphasize Claude 3’s strong performance and safety in real-world tasks. Successful adoption requires governance, testing, and human oversight. Organizations that refine prompt design and monitoring achieve measurable productivity gains. As a cutting-edge AI chatbot for 2025, Claude 3 enhances both creativity and routine workflows. Always validate outputs and monitor updates before making critical decisions with the model.

How AI with multiple personalities enables systems to adapt behaviors across user roles and tasks

Effective AI governance ensures fairness and safety by defining clear thresholds, tracking performance, and fostering continuous improvement.

Explore the truth behind AI hallucination and how artificial intelligence generates believable but false information
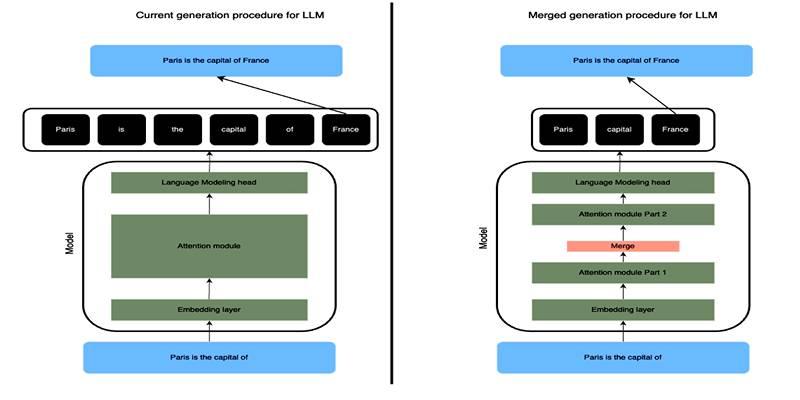
Learn how SLERP token merging trims long prompts, speeds LLM inference, and keeps output meaning stable and clean.

How to approach AI trends strategically, overcome FOMO, and turn artificial intelligence into a tool for growth and success.
Explore how Keras 3 simplifies AI/ML development with seamless integration across TensorFlow, JAX, and PyTorch for flexible, scalable modeling.

Craft advanced machine learning models with the Functional API and unlock the potential of flexible, graph-like structures.

How to avoid common pitfalls in data strategy and leverage actionable insights to drive real business transformation.

How neural networks revolutionize time-series data imputation, tackling challenges in missing data with advanced, adaptable strategies.
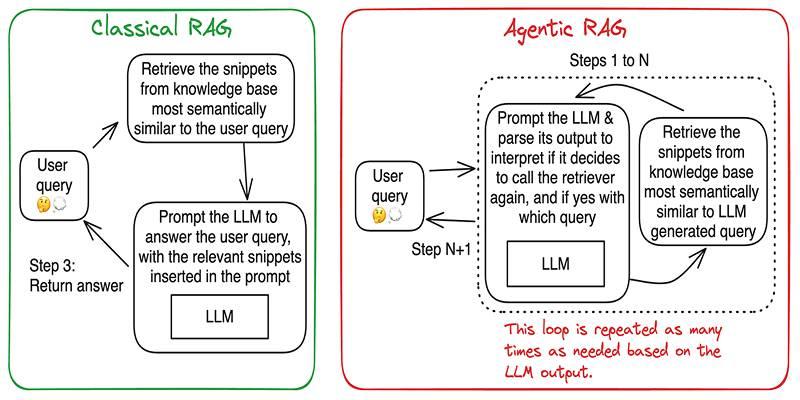
Build accurate, explainable answers by coordinating planner, retriever, writer, and checker agents with tight tool control.
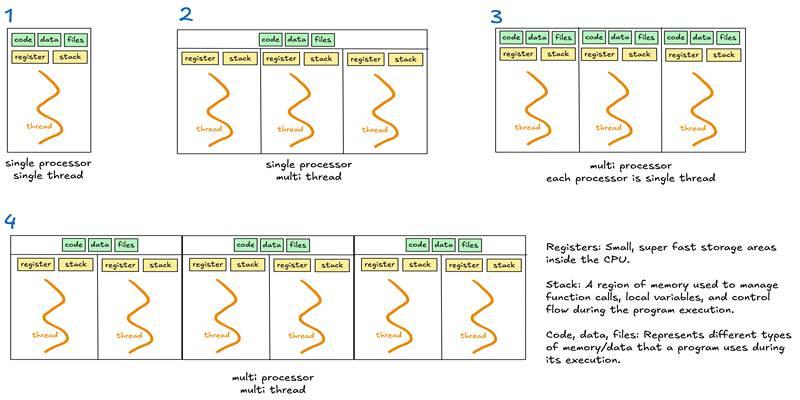
Learn when to use threads, processes, or asyncio to handle I/O waits, CPU tasks, and concurrency in real-world code.

Discover DeepSeek’s R1 training process in simple steps. Learn its methods, applications, and benefits in AI development