When people talk about artificial intelligence and vision… they usually end up talking about Convolutional Neural Networks. CNNs solved a problem that seemed impossible before. Computers once struggled to “see” anything beyond raw pixels. But CNNs flipped that. They gave machines a way to notice shapes, edges, and textures… almost like the human eye.
And now… CNNs have been the backbone of nearly every image-related breakthrough for a quite a while… from recognizing cats in photos to detecting tumors in scans. Let’s dig into the seven key reasons why CNNs dominate image tasks.
Let’s take the example of the human eye for this. Our eyes don’t scan an entire picture at once… they process small regions, then build the whole. Guess what CNNs do… exactly that!
CNNs adopt the same principle with local receptive fields. Instead of analyzing every pixel globally, they focus on small patches at a time. This is how they detect simple edges first, then combine those to form complex patterns.

It’s a layered way of understanding. A filter might pick out vertical lines, another catches curves, another highlights colors. Suddenly, the network builds a hierarchy of vision. Low-level features feeding into high-level recognition. This makes CNNs efficient and “biologically inspired.” It’s smart mimicry.
Traditional neural networks tried to connect every input to every neuron. For images with millions of pixels, this quickly became “unmanageable.”
CNNs introduced weight sharing. A trick where the same filter slides across the entire image.
This reduces the number of parameters drastically. Instead of learning millions of unique weights, the network learns a handful of reusable filters. The benefit is more than just efficiency… it’s consistency.
A cat’s whisker looks like a cat’s whisker no matter where it appears in the image. Weight sharing lets CNNs recognize patterns regardless of position. This subtle thing is why they scale so well.
A person recognizes a face whether it’s on the left side of a photo or the right. CNNs achieve the same ability through translation invariance. By applying filters across an entire image, they don’t care where the object lies; they’ll catch it.
This is huge for tasks like object detection or medical scans. A tumor in one corner of an MRI is still a tumor. A traffic sign in the top-left of a dashcam frame is still a traffic sign. CNNs don’t memorize pixel positions; they generalize spatially. That’s what gives them robustness in messy, real-world imagery.
One of the most powerful aspects of CNNs is their layered structure. Early layers learn primitive patterns like edges or colors. Deeper layers combine those primitives into shapes, then objects, then entire scenes.
This hierarchy mirrors how humans interpret visuals. We don’t jump straight to “that’s a car.” We, technically, first see edges, then contours, then combine those clues until the concept forms. CNNs layer that logic mathematically. The beauty is that no one handcrafts features anymore. The network discovers them. This shift from manual feature engineering to automatic feature learning is why CNNs overtook older approaches so decisively.
Pooling layers often get overlooked, but they’re critical because they reduce the resolution of feature maps. This is achieved with the help of the process called “summarizing regions” (like max pooling, which picks the strongest activation).
The result? A more compact representation that’s less sensitive to noise or minor distortions.
For example, think of an image that’s slightly blurred, rotated in a weird way, shifted oddly, etc. Without pooling, the network might lose track. With pooling, it still holds onto the most important signals in an image, regardless of the circumstances. Not only does this process make CNNs efficient, but it also means they stay stable even in the most unpredictable conditions.
Essentially, it’s a balance of two things: compressing data and retaining meaning. That tradeoff allows CNNs to scale without breaking down.
CNNs don’t just dominate individual tasks—they dominate across domains because of transfer learning. A model trained on millions of everyday images (like ImageNet) learns features that are surprisingly reusable.
Edges, textures, object parts… these patterns are universal. A CNN that learns them while classifying animals can transfer that knowledge to other fields like medical imaging, satellite analysis, industrial defect detection… you name it.
Instead of starting from scratch, scientists fine-tune pre-trained CNNs on smaller datasets. This reduces training time, saves time & resources, and yet delivers high accuracy. Reusability is power… and CNNs are perfect for it.
CNNs have proven themselves in competition after competition, benchmark after benchmark. From AlexNet in 2012 to ResNet and EfficientNet later, CNNs have consistently pushed the state of the art.

This success created an ecosystem. Libraries, pre-trained models, frameworks, and countless tutorials. Newcomers can now stand on the shoulders of giants without needing to “reinvent the wheel.”
It’s the momentum it carries. When a method is reliable, reproducible, and widely supported, it becomes the default choice… the new normal. CNNs have reached that point… and that’s why they still dominate.
A: Vision Transformers are definitely powerful new architectures that have achieved “state-of-the-art” results these days on some benchmarks. However, to say… they are strictly "better" is complex. CNNs still dominate in many scenarios.
A: Kind of, but not really. For example… Training a large CNN from scratch on a massive dataset (like ImageNet) requires significant computational power, almost always involving GPUs or TPUs. But, here’s the thing: for many practical applications, you can use something called “transfer learning.”
A: CNNs are incredibly versatile. Their ability to just “see” features makes them irreplaceable for computer vision tasks for the time being. Tasks other than image classification include:
Convolutional Neural Networks solved computer vision. Local receptive fields, weight sharing, invariance, hierarchy, pooling, transfer learning, and a proven track record… each reason basically stacks onto the next. So far, CNNs have been clear-cut winners for the past decade in computer vision… and they continue to hold that domination. And that too with no clear-cut competition (or contender) in sight.

How AI with multiple personalities enables systems to adapt behaviors across user roles and tasks

Effective AI governance ensures fairness and safety by defining clear thresholds, tracking performance, and fostering continuous improvement.

Explore the truth behind AI hallucination and how artificial intelligence generates believable but false information
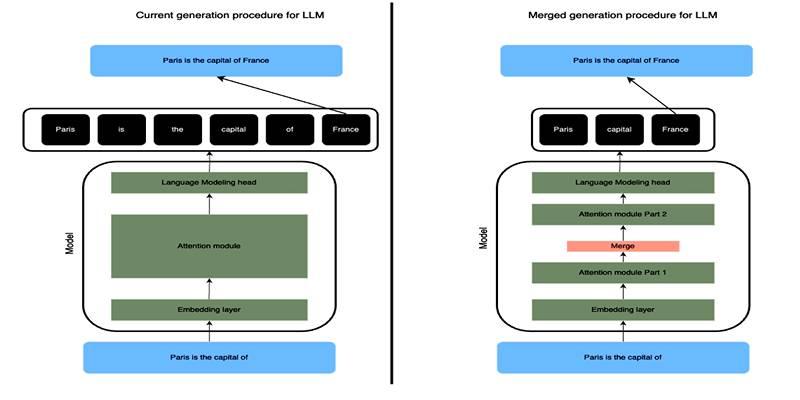
Learn how SLERP token merging trims long prompts, speeds LLM inference, and keeps output meaning stable and clean.

How to approach AI trends strategically, overcome FOMO, and turn artificial intelligence into a tool for growth and success.
Explore how Keras 3 simplifies AI/ML development with seamless integration across TensorFlow, JAX, and PyTorch for flexible, scalable modeling.

Craft advanced machine learning models with the Functional API and unlock the potential of flexible, graph-like structures.

How to avoid common pitfalls in data strategy and leverage actionable insights to drive real business transformation.

How neural networks revolutionize time-series data imputation, tackling challenges in missing data with advanced, adaptable strategies.
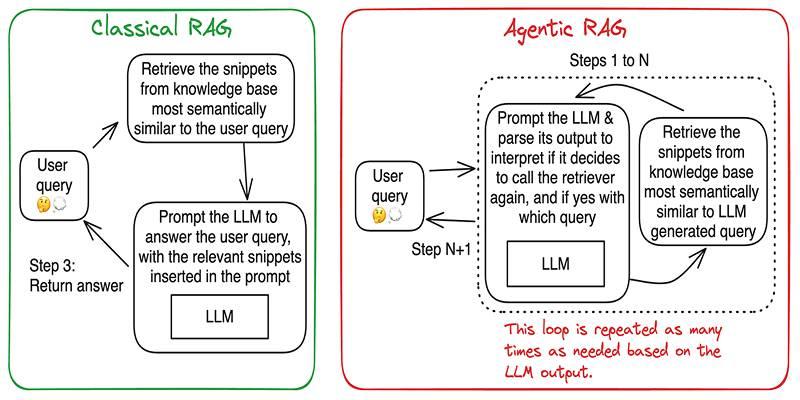
Build accurate, explainable answers by coordinating planner, retriever, writer, and checker agents with tight tool control.
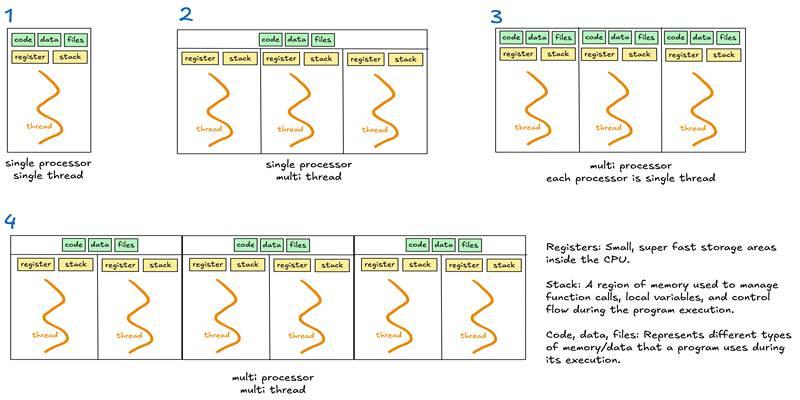
Learn when to use threads, processes, or asyncio to handle I/O waits, CPU tasks, and concurrency in real-world code.

Discover DeepSeek’s R1 training process in simple steps. Learn its methods, applications, and benefits in AI development