Transformer models struggle with long sequences due to the significant computational demands they impose. Training is slow and costly because transformer attention has quadratic time complexity. Latte offers a sophisticated solution by introducing latent attention in transformers. It reduces computation time without sacrificing efficiency. This approach makes attention scale linearly in both space and time.
As a result, resource consumption drops and processing speeds improve. By projecting tokens into a smaller latent space, Latte distinguishes itself from other models. It efficiently coordinates attention between latent and visible tokens, avoiding the computational burden of full attention matrices. Researchers view Latte as a valuable advancement for long-context tasks. Its architecture is scalable, efficient, and streamlined. Real-world applications can now benefit from the capabilities of a linear-time transformer model.
Transformers compute attention for every pair of tokens. As a result, the computation time increases quadratically. More input tokens translate into much more processing, to put it simply. As a result, scaling the model for longer documents or larger inputs is challenging. Every token in the sequence needs to communicate with every other token. Large attention matrices are produced. These matrices require more power and memory. The strain on the system increases with the amount of input.
It becomes a major obstacle in lengthy text passages or video frames. High computational costs limit deployment options. Researchers have experimented with low-rank techniques and sparsity. However, the majority result in performance trade-offs. Latent attention in transformers was developed in response to the need for a quicker, more intelligent approach. It provides a viable substitute that successfully and economically addresses the main bottleneck.
A limited number of trainable latent tokens is used in latent attention. These serve as intermediaries for the visible tokens. Instead of speaking directly to one another, each visible token communicates with the latent ones. Information is then shared between the latent and visible tokens. The computation is kept light by this two-step attention. Processing every pair of tokens is not necessary. It reduces the complexity from quadratic to linear.
Latte employs N × M and M × N interactions in place of N × N interactions. The latent token count, M, is substantially less than N. Linear scaling is the outcome of this. Another advantage of latent attention is that it maintains global context. High-quality, meaningful attention signals are still sent to tokens. The model learns rich representations at a low cost. That’s what an effective transformer attention mechanism, like Latte, is all about.

For improved performance, Latte offers a few noteworthy innovations. It first combines cross-attention layers with latent attention. This combination enhances token interactions at all levels. Second, it initializes latent tokens using a unique technique. It ensures more efficient training and improved outcomes. Third, it uses weight-sharing strategies to lower the number of parameters. It keeps the model small and training simple.
Latte also supports parallel attention computation. It is therefore more compatible with contemporary GPUs. The model achieves cutting-edge speed and accuracy with these features. Its simple design facilitates integration with current transformer frameworks. It doesn’t require significant rewrites for developers to use. For practical uses, that is a victory. Latte is fully in favor of production moving toward the linear time transformer model.
Effective models are required for long-sequence tasks such as genomics, video processing, and document comprehension. Conventional transformers choke on the size of the input. Latte’s latent attention neatly resolves that issue. It first enables models to grow without requiring additional memory. Second, it keeps expenses low while maintaining high accuracy. Thirdly, it facilitates training for sequence lengths longer than 10,000 tokens.
End-to-end performance has improved for use cases that previously required trimmed inputs. More context is helpful for NLP tasks, such as QA and summarisation. The same is true for vision tasks that call for complete image sequences. The linear structure facilitates faster inference times. In real-time applications, that is helpful. Cloud deployments are getting more affordable and environmentally friendly. Longer, deeper models that were previously impossible to train effectively are now possible thanks to latent attention in transformers.
Several models aim to address the inefficiencies of transformers. Longformer, Linformer, and Performer all provide fresh attention-grabbers. However, the majority entail compromises. Some drop context quality. Others require intricate tuning. Latte maintains simplicity and scalability. On many metrics, it is more accurate than Performer. Additionally, it preserves long-range context better than Linformer. It doesn’t rely on hashing, which can overlook important signals, unlike Reformer.
Latte’s structure is more akin to that of traditional transformers. It facilitates the transition without requiring significant rework. It outperforms many competitors in terms of training speed and accuracy. Benchmarks demonstrate consistent gains in both vision and text tasks. Latte is a good option if you’re looking for a linear time transformer model with fewer compromises.
In fields that require extensive comprehension, Latte performs admirably. It aids in genome sequencing in the medical field. It accurately processes multi-page legal documents. It enhances the creation of feedback in the classroom compared to lengthy essays. Latte’s structure speeds up scene detection and video classification. AI agents can now process complete documents and conversations in a single pass. It enhances memory and reasoning, facilitating more effective user interaction.
Latte examines time-series data and transaction logs in the finance industry. It uses less hardware while providing real-time insights. Chatbots use it to provide more context in lengthy conversations. Scalable AI that works effectively on edge devices is what many businesses are seeking. Here, too, Latte is helpful. It is perfect for on-device AI due to its low memory requirements and quick inference. Due to these practical requirements, an effective transformer attention mechanism is crucial.

Latte revolutionizes the construction and application of transformer models. High accuracy and linear scaling are made possible by its use of latent attention in transformers. Latte enables long-sequence processing by reducing computation time. It is ideal for tasks that require full-context input in science, NLP, and vision. Developers now have access to a potent tool that is quick, effective, and simple to use. Latte makes the linear time transformer model architectures of the future viable and practical. Compromise is no longer synonymous with efficiency. Everyone will benefit from improved models, from labs to the edge.

How AI with multiple personalities enables systems to adapt behaviors across user roles and tasks

Effective AI governance ensures fairness and safety by defining clear thresholds, tracking performance, and fostering continuous improvement.

Explore the truth behind AI hallucination and how artificial intelligence generates believable but false information
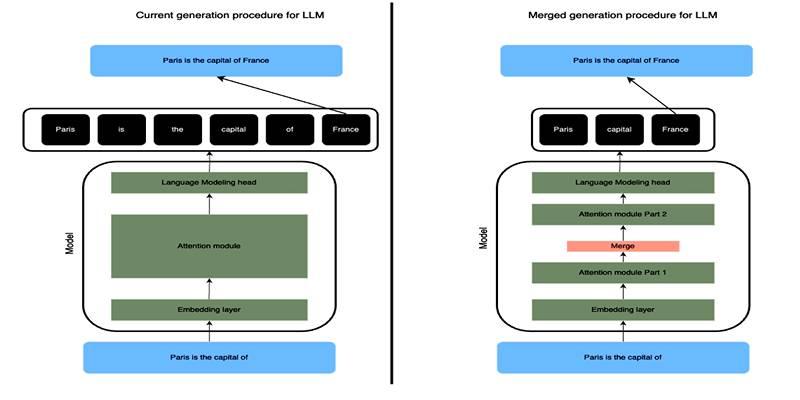
Learn how SLERP token merging trims long prompts, speeds LLM inference, and keeps output meaning stable and clean.

How to approach AI trends strategically, overcome FOMO, and turn artificial intelligence into a tool for growth and success.
Explore how Keras 3 simplifies AI/ML development with seamless integration across TensorFlow, JAX, and PyTorch for flexible, scalable modeling.

Craft advanced machine learning models with the Functional API and unlock the potential of flexible, graph-like structures.

How to avoid common pitfalls in data strategy and leverage actionable insights to drive real business transformation.

How neural networks revolutionize time-series data imputation, tackling challenges in missing data with advanced, adaptable strategies.
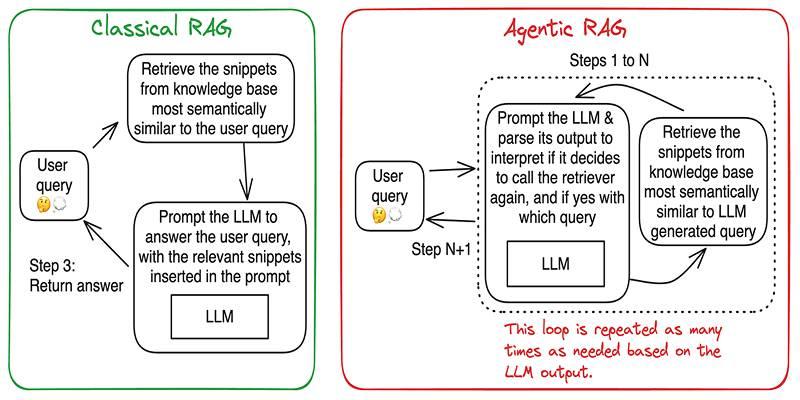
Build accurate, explainable answers by coordinating planner, retriever, writer, and checker agents with tight tool control.
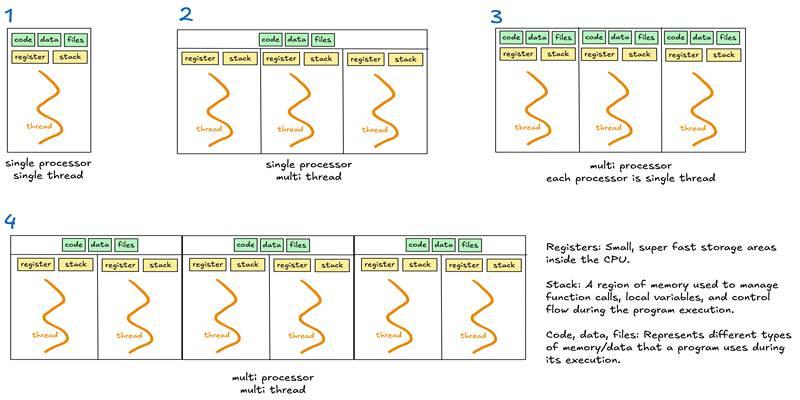
Learn when to use threads, processes, or asyncio to handle I/O waits, CPU tasks, and concurrency in real-world code.

Discover DeepSeek’s R1 training process in simple steps. Learn its methods, applications, and benefits in AI development