Artificial intelligence isn’t one-size-fits-all anymore. As AI systems interact with more people across more domains, a uniform approach stops working. A customer support bot for a bank handles different expectations than a productivity assistant in a startup. Even within the same platform, a beginner and an expert need different pacing, clarity, and depth.
These aren’t surface-level tweaks. Underneath the interface, systems need to interpret signals, align with context, and deliver responses that fit both the task and the person. That kind of flexibility demands changes in how models are built, how they’re run, and how their performance is measured.
When AI systems work across user groups, they start to depend on more than just input text. The same prompt from two users might require different reasoning paths. A first-time user typing “I need help with this report” might benefit from step-by-step support and follow-up questions. An experienced analyst might expect a compact answer with links to documentation and no redundant context. AI systems must account for these differences in subtle but reliable ways.
Context can come from many sources. Enterprise systems often pass structured metadata into the prompt, like user role, task, or past activity. In smart assistants, timing and environment play a role. A command from a child in the evening might trigger safety checks or simplified instructions. A parent issuing the same command in the morning could receive a more proactive sequence of actions.
This isn’t about personality in the human sense. It’s about modifying behavior to meet a specific situation. At the system level, this means calibrating tone, depth, and assertiveness. Too much variation, and the agent feels unstable. Too little, and it feels unhelpful. Finding a stable middle ground requires careful signal handling and conservative adaptation.
To make agents behave differently for different users, developers use three main techniques: fine-tuning, prompt conditioning, and modular orchestration.

Fine-tuning changes the model weights using specialized data. It helps when the task or user group requires deep domain expertise or unique reasoning styles. A legal assistant for compliance teams might need this to respond accurately under regulation. But fine-tuning introduces rigidity and scaling cost. Running dozens of separate models for different user types strains deployment budgets and complicates updates.
Prompt conditioning avoids this by adding behavior signals at runtime. These could be instruction blocks, examples, or metadata tags. A customer support bot might adjust its tone or level of detail based on user history, all without retraining the model. This works well for surface-level adaptation but doesn’t change deep reasoning patterns. It also adds latency. Longer prompts mean longer response times, higher token usage, and greater cost.
Modular systems take a different route. Instead of bending one model to serve everyone, they split responsibilities. One module handles classification. Another route to domain-specific agents. Each agent is optimized for a task or audience. For example, a helpdesk assistant might use one module to triage billing issues and another to answer technical questions. This keeps behavior consistent within tasks and allows updates without touching the core model. But it increases system complexity and creates more points of failure.
Each method serves a purpose. Prompt-based systems are fast to deploy and easier to maintain. Fine-tuned models are better for high-stakes or high-frequency users. Modular setups work best when multiple tasks and user groups must be supported in parallel.
Once agents adapt to users, old evaluation methods fall short. Measuring accuracy on static datasets no longer captures what matters. Instead, systems are judged on interaction quality, task completion, and long-term outcomes.
Cohort-based A/B testing is one approach. Different versions of an agent are deployed to user segments. Each group is monitored for patterns: how often they follow up, whether they rephrase questions, and how quickly they complete tasks. This gives insight into which behaviors support different users best. A tutoring assistant might be tested on whether users return after one session or finish their course faster. A sales tool might be judged on whether it shortens deal cycles.
Another approach is structured feedback. This includes explicit ratings, thumbs up/down, or flagged errors. But more often, implicit feedback matters more. Did the user click a link? Did they ask the same question again? These signals are noisy but plentiful. Used carefully, they shape system behavior without requiring human annotation.
Some systems apply reinforcement learning to optimize long-term interaction value. But this creates risk. Over-adaptation to a few users can degrade performance for others. Guardrails and throttling are needed to prevent erratic shifts. Systems that learn too quickly often end up producing behavior that feels unpredictable or mismatched.
Scaling adaptive behavior in real-world systems isn’t just a modeling problem. Deployment constraints are real. Inference cost rises with longer prompts. Fine-tuned models multiply storage and introduce version control problems. Privacy rules may block the use of user data altogether. Each constraint affects what kinds of adaptation are feasible.

Latency matters too. A customer chat system has strict limits. Even 300 milliseconds of delay can lower satisfaction scores. That limits how much customization can happen on the fly. Teams address this with template prompts, caching, or hybrid models that split fast and slow tasks.
Data control is another factor. Adaptive systems often need profile data, behavior logs, or metadata tags. But not all users consent to tracking. In regulated industries, personalization might need to happen without storing identifying data. This requires architecture that can load context on demand, use it temporarily, and discard it afterward.
The most successful systems aren’t the most personalized. They’re the most consistently helpful to the right people at the right time, using just enough adaptation to meet expectations. Shallow customization—tone, format, vocabulary—often delivers more benefit than deep personalization that adds cost or complexity.
AI agents adjust behavior based on purpose, familiarity, and context—not to mimic personality, but to be more effective. The challenge is finding the right balance between adaptability and stability. It requires knowing when to retrain, when to adjust prompts, and when to delegate tasks. Systems must also interpret feedback correctly and adapt without becoming unpredictable. As these systems scale, users value consistency and understanding over novelty. Reliable, context-aware responses define the true benefit of intelligent, adaptive AI.

How AI with multiple personalities enables systems to adapt behaviors across user roles and tasks

Effective AI governance ensures fairness and safety by defining clear thresholds, tracking performance, and fostering continuous improvement.

Explore the truth behind AI hallucination and how artificial intelligence generates believable but false information
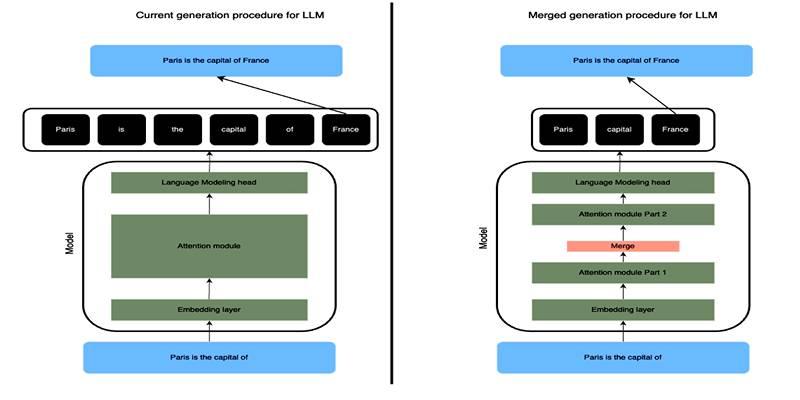
Learn how SLERP token merging trims long prompts, speeds LLM inference, and keeps output meaning stable and clean.

How to approach AI trends strategically, overcome FOMO, and turn artificial intelligence into a tool for growth and success.
Explore how Keras 3 simplifies AI/ML development with seamless integration across TensorFlow, JAX, and PyTorch for flexible, scalable modeling.

Craft advanced machine learning models with the Functional API and unlock the potential of flexible, graph-like structures.

How to avoid common pitfalls in data strategy and leverage actionable insights to drive real business transformation.

How neural networks revolutionize time-series data imputation, tackling challenges in missing data with advanced, adaptable strategies.
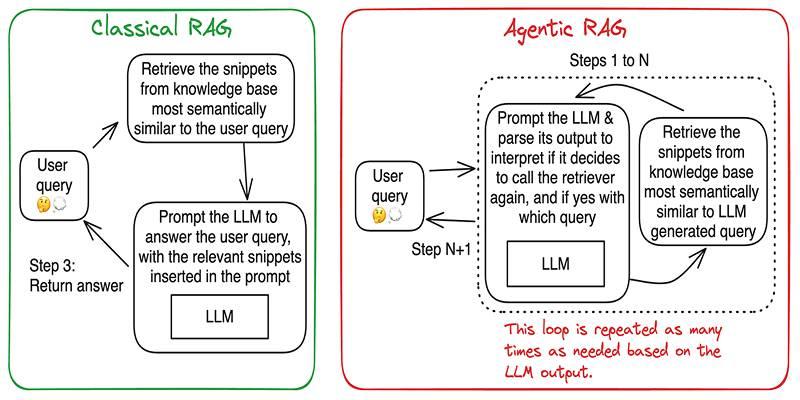
Build accurate, explainable answers by coordinating planner, retriever, writer, and checker agents with tight tool control.
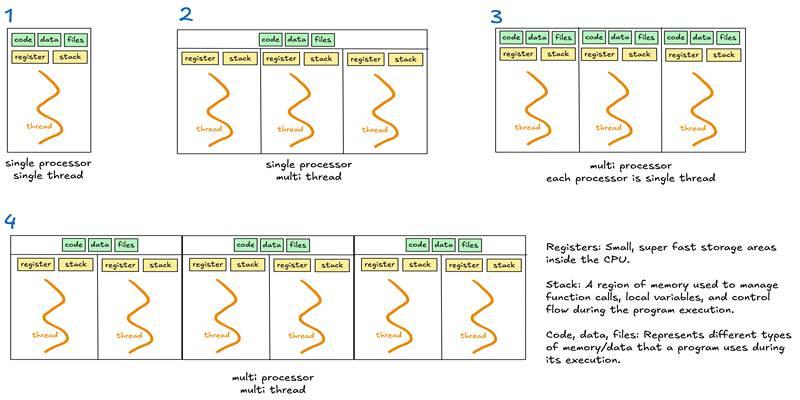
Learn when to use threads, processes, or asyncio to handle I/O waits, CPU tasks, and concurrency in real-world code.

Discover DeepSeek’s R1 training process in simple steps. Learn its methods, applications, and benefits in AI development