Time series data may include gaps that may lead to poor machine learning models and analysis. Starting with sensor data, banking information, or customer data, some vacuities must be filled with complex solutions. Neural networks provide an advanced imputation model; they address some exonerated patterns and non-linear links more advanced than conventional methods applied. This guideline covers time-series imputation based on neural networks, neural network hypotheses, and real-world strategies for filling data gaps.

Time-series data presents unique challenges that make standard imputation techniques inadequate. Sequential data carries temporal dependencies, where each observation relates to previous and future values in meaningful ways.
Basic techniques, such as forward-fill or backward-fill, can be biased, particularly in cases where data is missing in groups. Linear interpolation is based on the premise of smooth transitions, which can hardly usually occur in actual life situations. These methods do not utilize seasonal trends or the multifaceted dependencies that neural networks excel at capturing.
Factors of interest are more critical with applications. Different algorithms in financial trading require price forecasting, and the quality of healthcare monitoring systems should not be affected by sensor failure at the expense of patient safety. Neural networks have the complexity required to meet these challenging requirements.
Several neural network architectures work quite successfully in time-series imputation, and each of them has its advantages and applications.
The memory mechanisms of RNNs are natural for handling sequential data. Gated Recurrent Units (GRUs) and Long Short-Term Memory (LSTM) networks are used to model time series that can compute both short-term and long-term dependencies within a time series.
Bidirectional RNNs prove to be much more beneficial when it comes to imputation tasks because languages are processed both forward and backward. This method also enables the network to incorporate future observations into the process of predicting missing values, and in most cases, the precision is higher.
Transformer-based architectures have revolutionized time-series analysis, thanks to their attention mechanisms. Such models can determine the most relevant historical observations that can be used to predict missing values, irrespective of time and space.
The self-attention mechanism enables transformers to identify complex dynamics between various time points simultaneously. The ability to work with irregularly distributed datasets, or those with more than one seasonal component, gives them specific effectiveness.
Autoencoder designs generate condensed numbers of time-series data, and subsequently recreate the sequence. These models are based on patterns that learn to recognize significant temporal patterns that are replicated during complete data training.
To perform imputation, mask random values in the input sequence and train the auto-encoder to recreate the values elsewhere in the input sequence. Variational autoencoders introduce probabilistic aspects, which may allow for the quantification of imputed values of distortion.

A neural network imputation can be achieved successfully only after the appropriate data preprocessing. Normalize time series to obtain stable training, including transformations such as differencing to achieve stationarity.
Deceive training samples. This can be done by simulating missing values in entire sequences. With this model, you can test the quality of imputation into known ground truth values. Customize the missing patterns to the situations you encounter in the real world, such as random gaps, periodic outages, and burst failure.
Create a network architecture that can suit your data. In high seasonal data, add terms that may reflect various periodicities. Should your time series exhibit changes in trends, ensure that your model can learn such transitions.
Consider applying attention mechanisms to make your model pay attention to the most terrific historical observations. The former can be used to enforce the preservation of valuable information using skip connections within deep networks, and the latter can stabilize the training dynamics.
Adopt a multi-to-complete learning strategy in which your model will also learn to estimate future values and fill in missing values. This Mode of operation usually enhances performance on the two tasks as it promotes stronger temporal representations in the model.
The Times experimental validation sets are contaminated with synthetic missing data set patterns to check when the model is undergoing training. Stopping early using the accuracy of imputation can avoid overfitting and produce good generalization over the missing data cases that are not seen.
The scale of evaluation of the imputation quality must be evaluated very carefully, considering both the statistical performance and the utility. Basic accuracy measures, such as Mean Absolute Error (MAE) and Root Mean Square Error (RMSE), are not all-encompassing measurements.
Think of time, including metrics like distances between original and imputed sequences by means of Dynamic Time Warping (DTW). In instances where statistical characteristics are essential to the application, it can be tested that the imputed data retain the variance and correlation pattern, including distributional properties.
The issue of time-series data that contains time dependence makes cross-validation more complicated. Take advantage of time-conscious splitting functions that obey the chronological sequence of your information. More realistic performance estimates are provided by forward chaining validation, which involves systematically expanding the training window.
Imputation uncertainty is advantageous to production systems. Bayesian neural networks and ensemble technology can give confidence in imputed data, which can subsequently be used by downstream applications to have a fair understanding of the reliability of data.
Monte Carlo dropout provides a computationally practical system of recognizing uncertainties. It is possible to make distributions of conceivable imputed values by making several forward passes with varying imputations.
Many real-world scenarios involve multiple related time series. Joint imputation models that consider cross-series correlations often outperform univariate approaches. Graph neural networks can explicitly model relationships between different time series variables.
Mechanisms of attention across variables assisted models in determining which related series could provide the most helpful information to impute missing values in a target series.
Financial institutions use neural network imputation to handle missing price data and trading volumes. These applications require high accuracy because minor errors can compound into significant losses. Transformer-based models have shown particular success in capturing market dynamics and price relationships.
Industrial IoT scenarios often encounter sensor failures and communication disruptions. Manufacturing companies deploy LSTM-based imputation systems to maintain continuous monitoring of equipment health, using imputed values to trigger maintenance schedules and prevent costly downtime.
Healthcare applications demand both accuracy and interpretability. Hospitals use neural network imputation for patient monitoring data, where missing vital signs could indicate equipment failures or critical patient events requiring immediate attention.
Neural network-based time-series imputation outperforms traditional methods by capturing complex temporal patterns and handling non-linear relationships. Success relies on selecting exemplary architecture, validating strategies, and building adaptable systems. Start with clear objectives and test your approach with historical data to fine-tune performance. A pilot project ensures imputation quality before deployment, minimizing risks in production systems where missing data can have significant impacts.

How AI with multiple personalities enables systems to adapt behaviors across user roles and tasks

Effective AI governance ensures fairness and safety by defining clear thresholds, tracking performance, and fostering continuous improvement.

Explore the truth behind AI hallucination and how artificial intelligence generates believable but false information
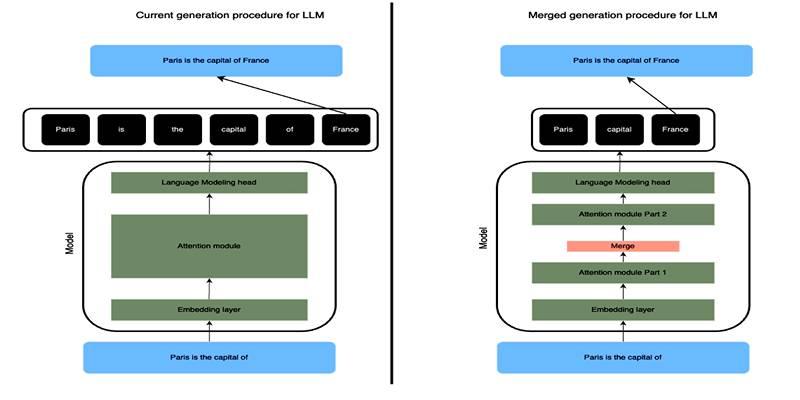
Learn how SLERP token merging trims long prompts, speeds LLM inference, and keeps output meaning stable and clean.

How to approach AI trends strategically, overcome FOMO, and turn artificial intelligence into a tool for growth and success.
Explore how Keras 3 simplifies AI/ML development with seamless integration across TensorFlow, JAX, and PyTorch for flexible, scalable modeling.

Craft advanced machine learning models with the Functional API and unlock the potential of flexible, graph-like structures.

How to avoid common pitfalls in data strategy and leverage actionable insights to drive real business transformation.

How neural networks revolutionize time-series data imputation, tackling challenges in missing data with advanced, adaptable strategies.
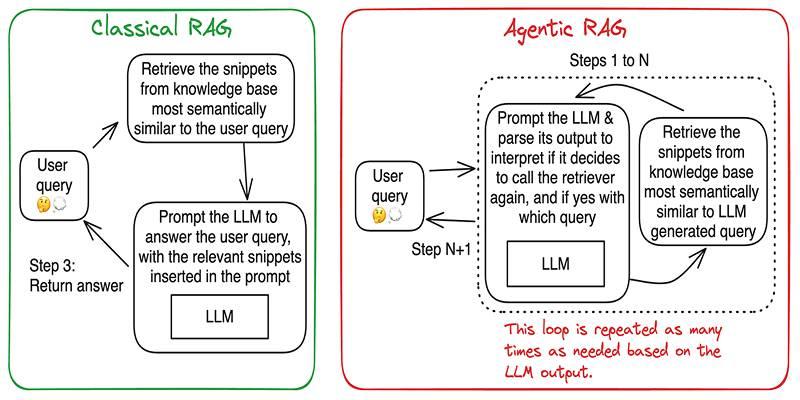
Build accurate, explainable answers by coordinating planner, retriever, writer, and checker agents with tight tool control.
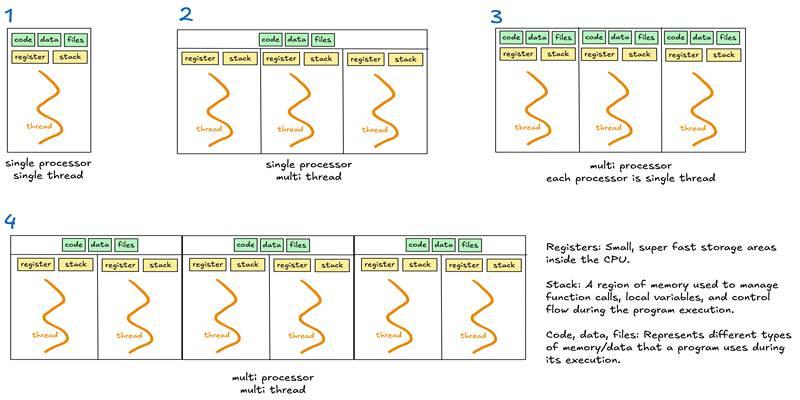
Learn when to use threads, processes, or asyncio to handle I/O waits, CPU tasks, and concurrency in real-world code.

Discover DeepSeek’s R1 training process in simple steps. Learn its methods, applications, and benefits in AI development