Multithreading, multiprocessing, and asyncio often get tossed into the same bucket, yet they solve different kinds of waiting. A thread is a lightweight path of execution that lives inside one process and shares its memory. A process is a program instance with its own memory space that your operating system schedules on CPU cores.
Asyncio is an event loop that runs many tasks on one thread by switching at await points. All three aim to keep your program busy rather than sitting idle while calls block on disks, networks, or long computations.

Threads shine when tasks must share in-memory state, and much of the time goes to waiting on I O. Because threads live inside one process, they can access the same objects without copying. That convenience comes with sharp edges.
Two threads can modify the same data at once unless you guard it. Locks, condition variables, and queues coordinate access, but misuse can cause deadlocks or stalls. In runtimes with a global interpreter lock, only one thread executes bytecode at a time, yet threads still help a lot for sockets and files because the runtime releases the lock while the operating system waits.
Processes give real parallel speed on multicore machines because each process runs on its own core with its own memory. That isolation improves safety and often simplifies reasoning about bugs. The trade is cost. Spawning a process is heavier than launching a thread. Sharing data requires serialization or shared memory tools.
If you pass large objects back and forth, the copying can erase the gains. Processes excel when the work is CPU bound, each unit of work is chunky, and tasks do not need constant shared state. When tasks are tiny and chatty, the glue code can outweigh the benefit.
Asyncio takes a different path. Tasks yield control at await points, which lets the event loop run something else while one task waits on a socket, a database, or a timer. Because all tasks share one thread by default, you avoid most locking headaches.
You also avoid the overhead of spinning up extra threads for every connection. The catch is simple. CPU heavy code blocks the event loop and starves other tasks. That means you either keep compute slices short, offload them to separate threads or processes, or redesign the flow so the loop can keep moving.
Pick the tool that matches your bottleneck. If the program waits on networks or files, threads or asyncio fit well because other work can continue while the operating system sits on I O. If the time goes to number crunching, processes fit better because they use multiple cores in parallel.
Threads work for I O. Processes work for CPU. Asyncio gives very high concurrency for I/O-bound servers without multiplying threads, but it is not a speed button for compute loops. Measure where the time goes, then match the model to that profile rather than to a trend.
Shared state is the classic source of bugs in threaded programs. Keep the locked region small and prefer queues that pass messages rather than passing raw object references around. In process based designs, think about message formats early and measure serialization costs with real payloads.
With asyncio, learn where libraries may block the loop and wrap such calls in executors when needed. Across all three models, think about back pressure. If producers generate work faster than consumers can handle, memory will balloon. Use bounded queues and let producers wait when buffers fill so the system stays stable.

Good tests force the tricky edges to show up on your laptop instead of in production. Use small sleeps or fakes that control timing to explore races. Seed randomness and log thread names, process IDs, and task IDs so you can follow a single request across components. Metrics beat guesswork. Track queue sizes, task counts, and time spent waiting versus time spent working.
A simple chart that shows backlog next to service time will tell you more than a wall of stack traces. When refactoring, move one boundary at a time and keep a kill switch so you can roll back cleanly.
Different platforms use different process start methods and have different default event loops. Code that flies on one machine might crawl or behave oddly on another. Favor standard libraries and mature frameworks that hide such differences cleanly.
Read the footnotes about signals, subprocess handling, file descriptors, and shutdown order, because small details there cause outsized pain. Finally, factor in the team. A slightly slower design that everyone can read and debug often wins against a fragile speed trick that only one expert understands. Sustainability is part of performance.
Frameworks like FastAPI, Flask, Django, and Celery each favor different concurrency models. FastAPI is built on asyncio and supports async functions out of the box, but CPU-heavy tasks still require offloading to thread or process pools. Django, being synchronous, often uses multiprocessing or external queues like Celery for background work. Flask, while flexible, usually depends on external tools for concurrency management.
Effective integration goes beyond choosing the right model—it requires aligning with the framework’s lifecycle, middleware, and shutdown behavior. Mismatched shutdown hooks or mixing signal handlers with threads can lead to deadlocks or zombie tasks. Understanding your framework’s concurrency philosophy is crucial, as poor integration often causes more issues than the concurrency model itself.
Threads, processes, and asyncio each solve waiting distinctly. Threads share memory and suit I/O-bound tasks, but they need careful coordination to avoid races. Processes bring true parallel speed for CPU bound jobs and add safety through isolation, at the cost of heavier startup and data passing.
Asyncio delivers high concurrency on one thread by switching at await points, which keeps I/O-bound programs moving without lock drama as long as you keep compute work off the loop. Profile your code, choose by the waiting you see, and design for stability so your program stays fast and calm under load.

How AI with multiple personalities enables systems to adapt behaviors across user roles and tasks

Effective AI governance ensures fairness and safety by defining clear thresholds, tracking performance, and fostering continuous improvement.

Explore the truth behind AI hallucination and how artificial intelligence generates believable but false information
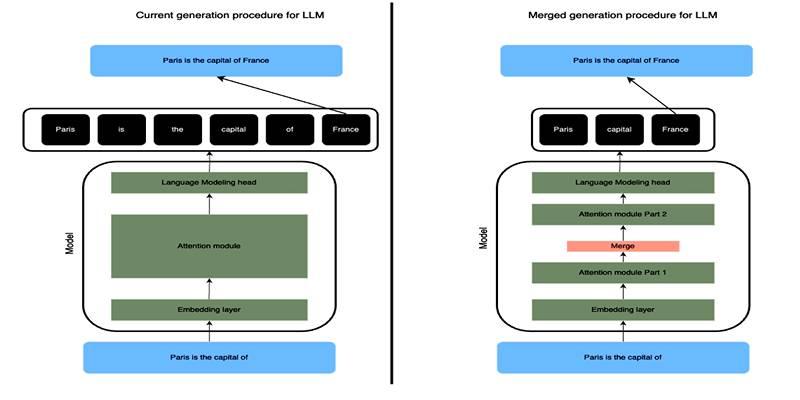
Learn how SLERP token merging trims long prompts, speeds LLM inference, and keeps output meaning stable and clean.

How to approach AI trends strategically, overcome FOMO, and turn artificial intelligence into a tool for growth and success.
Explore how Keras 3 simplifies AI/ML development with seamless integration across TensorFlow, JAX, and PyTorch for flexible, scalable modeling.

Craft advanced machine learning models with the Functional API and unlock the potential of flexible, graph-like structures.

How to avoid common pitfalls in data strategy and leverage actionable insights to drive real business transformation.

How neural networks revolutionize time-series data imputation, tackling challenges in missing data with advanced, adaptable strategies.
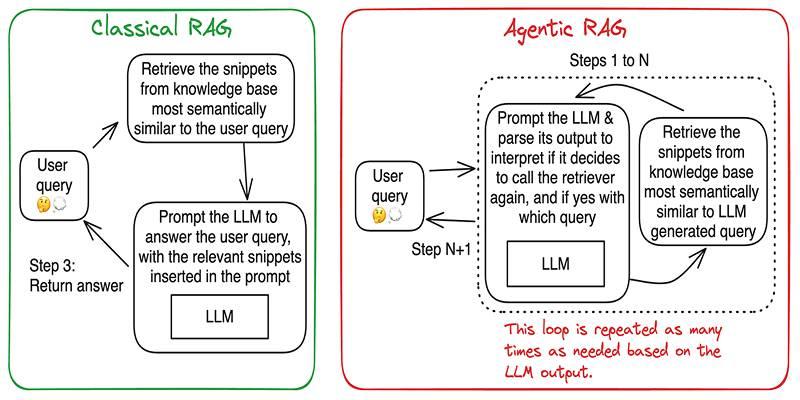
Build accurate, explainable answers by coordinating planner, retriever, writer, and checker agents with tight tool control.
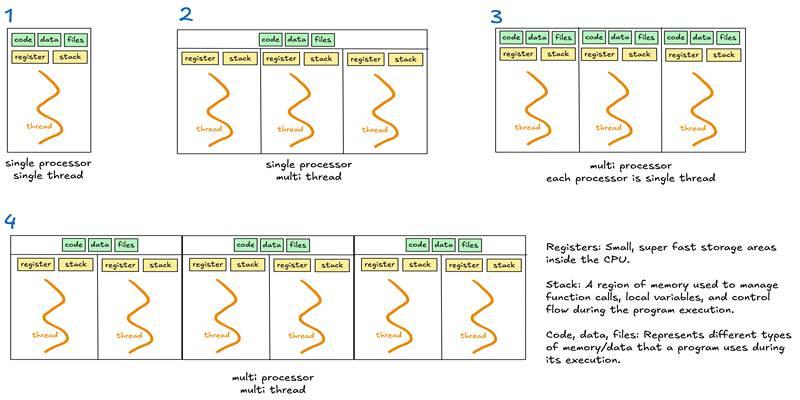
Learn when to use threads, processes, or asyncio to handle I/O waits, CPU tasks, and concurrency in real-world code.

Discover DeepSeek’s R1 training process in simple steps. Learn its methods, applications, and benefits in AI development