AI performance measurements based on accuracy, precision, and recall have been in use over decades. However, with the advancement in the sophistication of AI systems and their increased importance to our lives, these conventional standards are not sufficient any longer. They have the capability to conceal such important weaknesses as bias or lack of practical strength. It is high time to stop the simplistic measures and Direct towards more holistic ones.

In order to know where we should go, we cannot avoid knowing what the faults of our past have been. Model evaluation based on metrics such as accuracy, precision, and F1-score has continued to be a mainstay of model evaluation over the years, yet its shortcomings are becoming more and more obvious.
Accuracy is used to measure the correct predictions among all predictions. Although this may sound simple and intuitive, when dealing with an imbalanced dataset, it may be misleading.
Take an example of AI model that is created to identify a rare disease with a prevalence of 1 out of 100 individuals. A model that can be used to predict that there is no disease in all individuals would have 99% accuracy. On paper this appears to be a gorgeous success. As a matter of fact, the model makes no sense whatsoever as it does not pinpoint any of the real positive cases. This example shows how precision may give a deceptive illusion of safety and inability to reflect the genuine usefulness of the model.
Precision and recall offer a more nuanced view than accuracy, particularly in classification tasks.
The precision and recall can oftentimes be traded off. As an illustration, in spam detection, you may have a bias on high accuracy so that you are confident that you will not have any important email being identified as spam. High recall is essential in screening of medical cases in order to eliminate the possibility of missing any feasible cases even after a higher number of false positives. It tries to strike a balance by the F1-score that is the harmonic mean of precision and recall. Nevertheless, even such measures fail to represent the entire picture of the performance of a model in a real-life situation.

In order to develop AI systems that are both technically skilled and responsible and effective, we require a more comprehensive evaluation framework. This entails the integration of measures that determine fairness, strength and interpretability.
Among the largest issues of AI is the ability to make sure that models will not reproduce or increase the level of the existing bias existing in the society. An AI that handles loan applications, say, would be subject to learning the historical data to discriminate against specific demographic groups unfairly.
In order to counter this, we should be proactive in gauging fairness. A number of measures have been established to measure bias:
This metric will verify whether the fraction of positive predictions is identical in distinct groups (e.g. gender). This model is assumed to be fair in the case when chances of getting a loan are also not related to the group of clients.
This measure is used to make sure that the true positive rate (recall) is consistent in the various groups. That is, the model should target them at the same rate irrespective of their group to all the people who are actually qualified to take a loan.
This tests whether there is the same number of false positives among groups. It provides the assurance of the same people of various groups who are not qualified to be as likely to be falsely categorized as qualified.
The appropriate metric of fairness will have to be selected based on what the context and application aims are and what ethical objectives are. None of these metrics can be considered a perfect one, and in many cases, one may have to take several definitions of fairness into account at some time.
The application of AI model that works in a controlled lab setting might not work in the real world. This may be due to the fact that real world information is usually sloppy, unstable, and may evolve, a process known as data drift. A strong model is a model that is able to retain its functionality when subjected to noisy or adversarial inputs.
Testing for robustness involves several techniques:
It will entail purposely feeding the model with slightly altered inputs with the aim of deceiving the model to make erroneous predictions. An example is that when few pixels are altered in an image this may lead to misidentification of an image by an image recognition model. Pushing the model against these attacks will assist in the measurement of the resilience of the model.
This does this by checking the performance of the model on out-of-distribution (OOD) data, which is data that is not the one the model is trained on. This is modeling the way the model would respond to some possible new unknown situations.
Changes in input data need to be constantly observed after its implementation. The data should not deviate considerably with the training data otherwise the model will not perform well and may require to be retrained.
With increasingly complex AI models, especially deep learning models, it is likely that they will turn into black boxes. We are aware of the inputs and the outputs but not the logic behind the decisions they make. A significant impediment to this aspect of non-transparency, particularly in high-stakes sectors such as healthcare and finance, is that such explanations are legally and ethically mandatory.
Interpretability or Explainable AI (XAI) aims at creating ways of comprehending and confiding in the outcomes produced by machine learning algorithms. Individual prediction can be explained with the help of such techniques as LIME (Local Interpretable Model-agnostic Explanations) or SHAP (SHapley Additive exPlanations). As an example, they are able to point out the most influential features (e.g., the income, credit score) that had the most impact when deciding which loans a model would approve or reject. With interpretable models, we can better debug the model, can better align our expectations with the model and can achieve trust with our users.
Translating metrics into actionable insights requires a comprehensive framework. Move beyond mere reporting to foster continuous evaluation and improvement. Establish clear AI governance, defining acceptable thresholds for fairness, robustness, and accuracy before model deployment. Implement feedback loops to track post-deployment performance, informing future iterations. The ultimate goal is a comprehensive dashboard of indicators, offering a 360-degree view of AI system impact, ensuring powerful, safe, and fair outcomes.

How AI with multiple personalities enables systems to adapt behaviors across user roles and tasks

Effective AI governance ensures fairness and safety by defining clear thresholds, tracking performance, and fostering continuous improvement.

Explore the truth behind AI hallucination and how artificial intelligence generates believable but false information
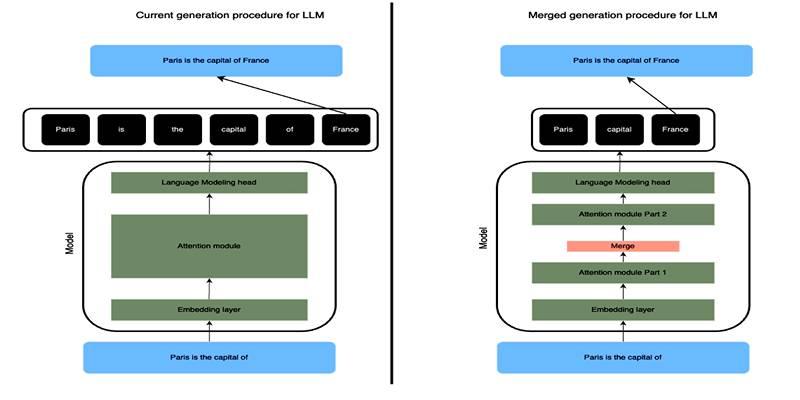
Learn how SLERP token merging trims long prompts, speeds LLM inference, and keeps output meaning stable and clean.

How to approach AI trends strategically, overcome FOMO, and turn artificial intelligence into a tool for growth and success.
Explore how Keras 3 simplifies AI/ML development with seamless integration across TensorFlow, JAX, and PyTorch for flexible, scalable modeling.

Craft advanced machine learning models with the Functional API and unlock the potential of flexible, graph-like structures.

How to avoid common pitfalls in data strategy and leverage actionable insights to drive real business transformation.

How neural networks revolutionize time-series data imputation, tackling challenges in missing data with advanced, adaptable strategies.
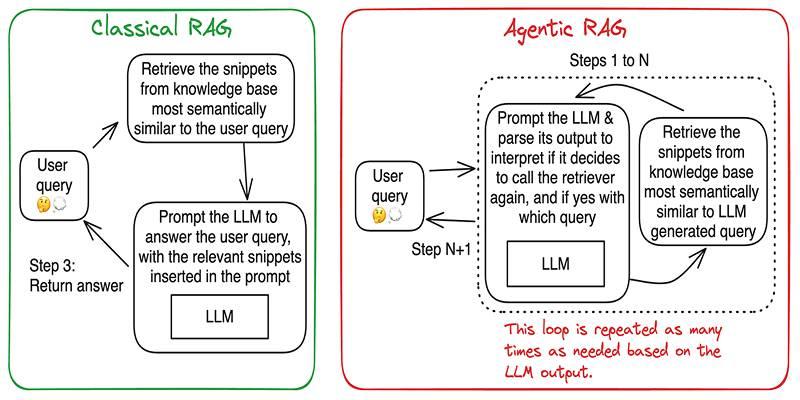
Build accurate, explainable answers by coordinating planner, retriever, writer, and checker agents with tight tool control.
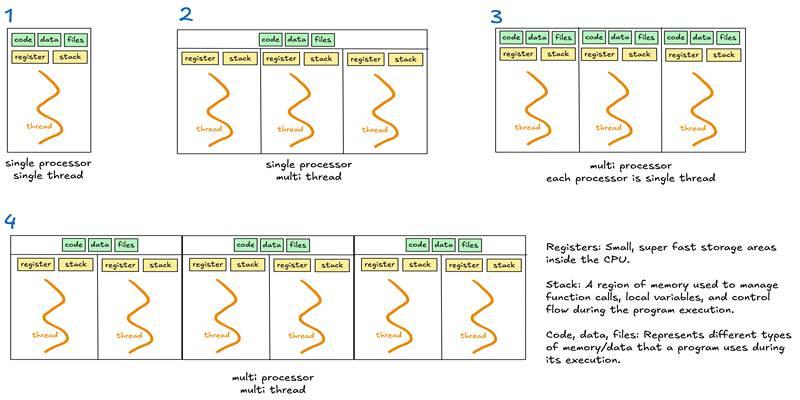
Learn when to use threads, processes, or asyncio to handle I/O waits, CPU tasks, and concurrency in real-world code.

Discover DeepSeek’s R1 training process in simple steps. Learn its methods, applications, and benefits in AI development